Introduction
Energy efficiency has been a critical point of research in multiple areas of computer architecture, including processor design, memory hierarchy, and power management. This paper focuses on technical solutions for x86, ARM, and GPU architectures, and how novel techniques are used to overcome the challenges of energy efficiency. The demand for high-performance computing systems has led to a significant power consumption that engineers aim to address through innovative optimization of existing and theoretical computer architecture.
This paper is organized into multiple sections that describe new technologies leveraging innovative approaches to system architecture, prioritizing improved performance, greater flexibility, and better power efficiency. These sections include Performance-Hybrid Architecture, Chiplets, and Analog Matrix Multiplication. By optimizing the performance and energy output of these architectures, it is deemed critical that research and development of energy efficiency in x86, ARM, and GPU architectures is pursued to determine the most effective design strategies for future computing systems.
Background
Processor technology has encountered several challenges, including the breakdown of Moore's law. According to Moore's law, the number of transistors on a chip doubles approximately every two years, resulting in increased performance. However, this progress is hindered as the size of transistors reaches the atomic scale, making it impossible to continue increasing performance by shrinking transistors. This obstacle leads to higher manufacturing costs for larger chips, which can cause more defects and lower yields.
Another challenge that the industry faces is the demand for efficient machine learning algorithms while minimizing energy consumption. As these algorithms become increasingly complex, it is essential to find innovative solutions to improve performance and energy efficiency.
To overcome these challenges, processor technology requires novel approaches to optimize performance and energy efficiency. This paper explores the technical solutions for x86, ARM, and GPU architecture, emphasizing innovative solutions such as Performance-Hybrid Architecture, Chiplets, and Analog Matrix Multiplication. These novel technologies leverage new approaches to system architecture to prioritize improved performance, greater flexibility, and better power efficiency.
Survey Methodology
This survey paper follows a systematic methodology to identify and analyze the existing literature on energy-efficient computing technologies in x86, ARM, and GPU architectures. The search for relevant articles was conducted using various online databases, including IEEE Xplore, ACM Digital Library, Google Scholar, as well as industry white papers.
To identify relevant articles, we used a combination of keywords and search terms, such as "energy-efficient computing," "processor architecture," "performance-hybrid architecture," "chiplets," "analog matrix multiplication," "x86," "ARM," and "GPU." We limited the search to articles published between 2015 and 2023 to ensure that our survey reflects the most recent developments in this field.
After applying the inclusion and exclusion criteria, we selected a number of articles that met our research objectives. We then conducted a qualitative analysis of the selected articles, focusing on the technical solutions proposed for improving energy efficiency in x86, ARM, and GPU architectures. We also analyzed the strengths and limitations of each solution and identified the common themes and trends in the literature.
Our data analysis method involves categorizing and summarizing the findings, and organizing them into subsections based on the identified themes. To ensure the accuracy and validity of the data, we followed a rigorous process of data extraction and analysis, with at least two reviewers involved in the screening and selection process.
Overall, our survey methodology ensures that our paper presents a comprehensive and objective overview of the existing literature on energy-efficient computing technologies in x86, ARM, and GPU architectures.
Solutions
CPU: x86 & ARM Improvements
This section will discuss energy reduction methods found in x86 and ARM CPU architectures. These methods include chiplets and performance hybrid architecture. Analog matrix multiplication will also be discussed in the presentation, though it should be noted that this method can not be found in current consumer products.
Chiplets
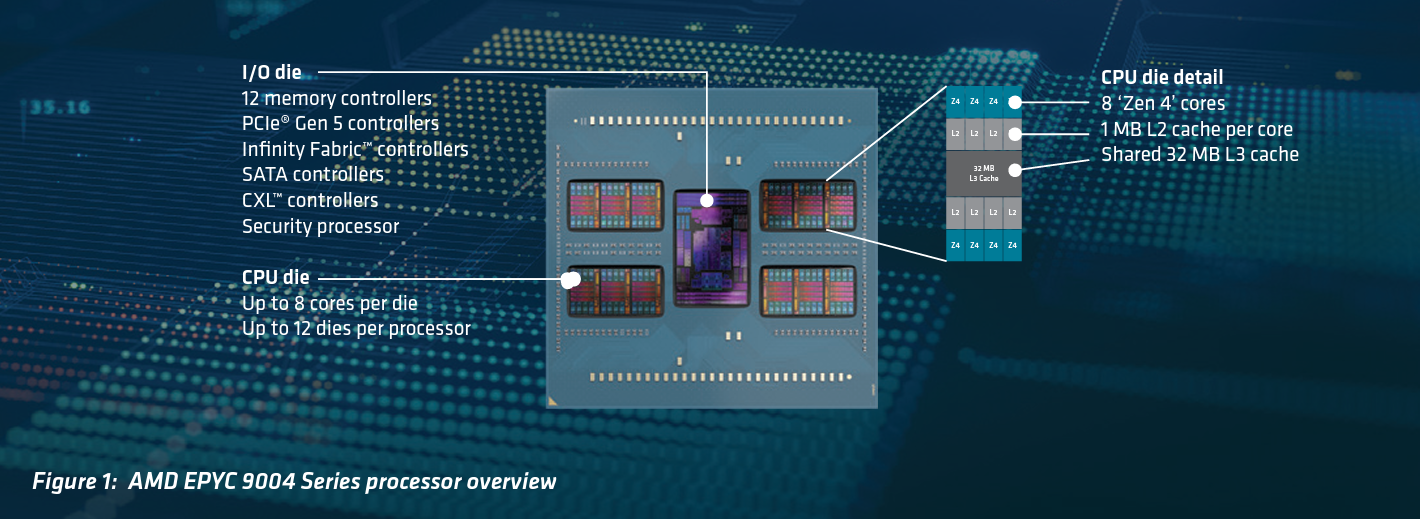
Chiplets are smaller chips that can be integrated to form a larger circuit, providing easier scaling of processors, modularity, and reducing manufacturing costs. Chiplets also provide energy efficiency as certain chiplets can be disabled and powered down when not in use. However, the implementation of chiplets can also increase power consumption, such as in the interconnect, where the I/O chip can use a significant amount of energy managing everything going in and out of all the chiplets.
Performance Hybrid Architecture
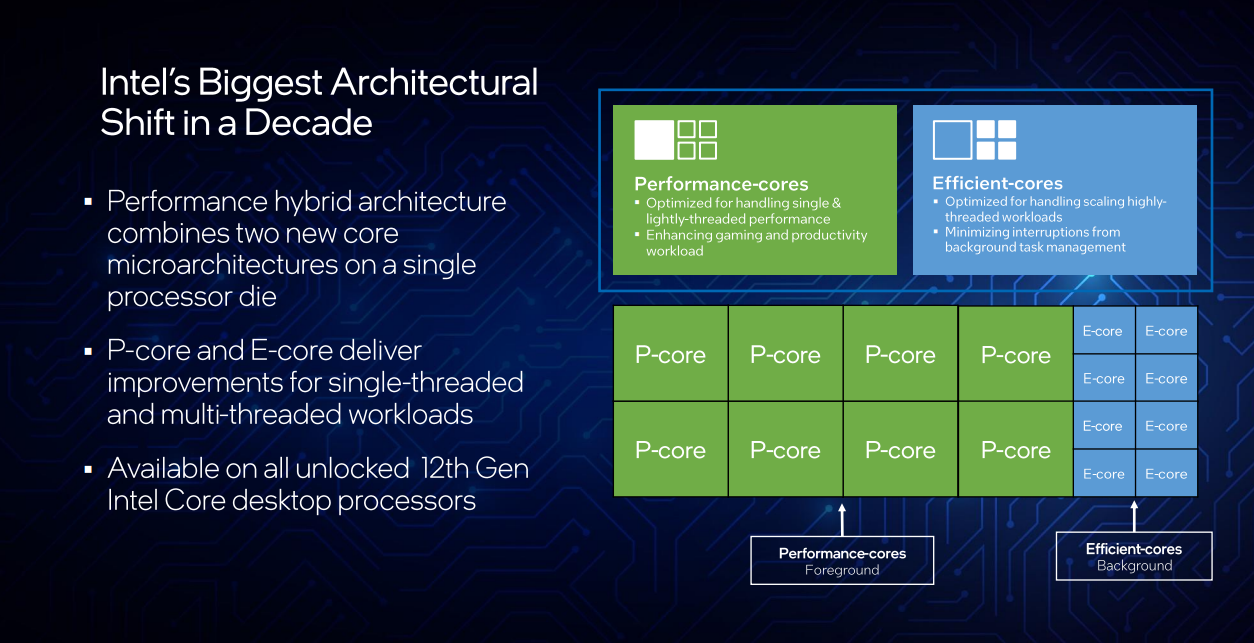
Another solution is the performance hybrid architecture, which uses a mix of smaller, cheaper, and power-efficient cores alongside bigger, more expensive, and power-hungry cores. The hybrid architecture provides an efficient and powerful computing experience by optimizing the P-cores for single-thread performance and the E-cores for multi-threaded performance. The E-cores handle low-priority tasks, while the P-cores handle high-priority and complex tasks, resulting in improved performance and energy efficiency.
CPU-GPU Architectures
One of the most common hybrid architectures is the CPU-GPU architecture. In this architecture, the CPU handles the general-purpose computing tasks while the GPU handles the highly parallelizable tasks. The performance trade-off in this architecture is between the CPU's processing power and the GPU's parallel processing capabilities. The CPU has a high clock speed and can execute single-threaded tasks quickly, while the GPU has many more processing cores, allowing it to handle many threads simultaneously.
FPGA-CPU Architectures
Another hybrid architecture is the FPGA-CPU architecture. FPGAs are highly customizable and can be programmed to perform specific tasks. In contrast, CPUs are more versatile but lack the customization options of FPGAs. The performance trade-off in this architecture is between the CPU's flexibility and the FPGA's specialization. FPGAs can provide higher performance for specific tasks, but the CPU can handle a broader range of workloads.
ARM big.LITTLE Architecture
The ARM big.LITTLE architecture is another example of a hybrid computing architecture. This architecture combines high-performance and low-power cores in a single system-on-chip (SoC). The high-performance cores are used for demanding tasks, while the low-power cores are used for less demanding tasks to save power. The performance trade-off in this architecture is between the high-performance and low-power cores. The high-performance cores offer more processing power but consume more power, while the low-power cores consume less power but offer less processing power.
Performance Trade-Off Matrix

Intel uses a performance trade-off matrix that takes into account three factors: CPI (cycles per instruction), frequency, and voltage. The performance equation is Performance = CPI * Frequency * Voltage^2. This equation shows that the performance is very much impacted by voltage which in turns affects the energy efficiency. The matrix helps system designers optimize for specific workloads by adjusting the factors.
Analog Matrix Multiplication
Analog matrix calculates results via memory. Performing calculations with currents allows for continuous-time calculation in which digital signals are converted to analog and then back to digital. The energy that is used in transporting data to an external unit is also conserved since these calculations can be performed with the memory modules themselves[14]. However, this process is still under developmental research and is not currently under consumer production at the moment. The introduction of this kind of calculation into consumer electronics will likely show a significant improvement in energy efficiency and chip performance.
GPGPU & GPU Improvements
This section will discuss energy reduction methods found in general-purpose computing on graphics processing units (GPGPU) and GPUs. These methods include parallelism, variable memory hierarchy, incoherent caches, and precision selection.
Parallelism
Due to the GPU's relatively simple architecture and smaller size, it is especially well-suited for parallel computing. Such computing includes thousands of threads running in parallel. This parallelism increases performance per watt [15]. According to Alves et al., the process of parallelism, at a software level, allows the energy level and heat dissipation to be significantly reduced compared the same program running without parallelism. Alves et al. also proposed that with an increasing number of cores in processors becoming more likely to take over the current architecture landscape, power consumption is constantly increasing and therefore energy saving techniques in parallelism are very impactful in relation to high-performance computer architecture.
Memory Hierarchy
Due to the highly parallel nature of GPGPU computing, typical course-grained memory hierarchy can be rather ineffective. In coarse-grained architecture, each thread has a highly limited cache due to the number of total threads. Thus, miss rates are increased which decreases temporal locality and off-chip accesses become excessive and waste energy. This is especially true for programs with decreased amounts of locality. The use of fine-grained architecture can be seen in Figure A. Here, on a chip, there is not only an L1 Cache, but there is also a Shared Memory cache and Read-Only Data Cache. These small caches reduce the miss rate and distance data has to travel.
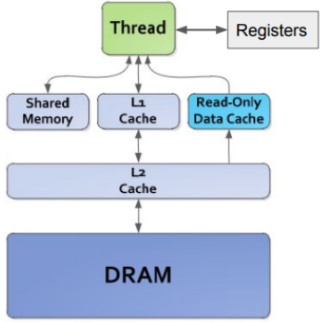 Figure A: GPU Memory Hierarchy (https://dlsys.cs.washington.edu)
Figure A: GPU Memory Hierarchy (https://dlsys.cs.washington.edu)
Rhu et al. took advantage of the variability in the locality of highly threaded GPU computing in the study “A Locality-Aware Memory Hierarchy for Energy Efficient GPU Architectures. They created a module that adjusts the granularity of memory allocation based on the predictions of the module called a Bi-Modal Granularity Predictor (BGP). This module does cost estimations for both temporal and spatial locality of missed cache blocks to determine and determines the granularity of the memory access that the system will perform. Coarse-grained access is used when requests are both spatially and temporally local and fine-grained access has used the rest of the time to avoid unnecessary data transfers, save power, and improve performance. [16]
Incoherent Cache
Although fine-grained architecture helps to address the cache issues that arise with high amounts of multithreading, some implementations can be more energy intensive than others. The Data Cache and Shared Memory that is implemented using scratchpad memory seen in Figure A can be extremely energy intensive. These modules must sustain requests from all lanes and coalesce memory, causing it to be very energy inefficient [17].
Sankaranarayanan et al. used small incoherent caches for individual lanes to substitute some of the uses of Data Cache and Shared Memory. This incoherent cache acts as a write-back cache which uses a write-validate policy to maintain correctness. This incoherent behavior is specifically helpful with Nvidia’s CUDA and OpenCL which create threads without explicit barriers and access the same cache line. Each incoherent cache was implemented with 16 entries and a 64B line size and the implementation of these caches accounted for about 9% of the area of the GPU on-chip memory hierarchy. These changes were implemented and compared with a control on nine algorithmic benchmarks including BFS, SGEMM, and Transpose. The IPC upon implementation remained very similar to the control, only showing an average reduction of 2.3%. In terms of energy consumption, the incoherent cache implementation showed on average a decrease in dynamic energy consumption of the on-chip memory hierarchy by 37% and a 35% reduction of an energy-delay product. The applications that benefited particularly well from the implementation were backdrop, SGEMM, SPMV, and SRAD. [17]
Precision Selection
Often energy efficiency can come at the cost of performance speeds, but architects can also choose to make systems save energy at the expense of correctness. Precision selection refers to the amount of acceptable error in arithmetic operations. Architects may decide that replacing more correct calculation modules with ones that are more energy efficient may be optimal for the specific system on which they are working. Such replacements include replacing multiplications by powers of two with shift operations and two-dimensional signal gating for bit-width multipliers [18]. Precision selection has been around for a long time and can be used in both CPUs and GPUs.
Pool et al. demonstrate the use of two precision selection methods. The first is a static approach that has guaranteed error bounds and builds a dependency graph that propagates the acceptable error backward toward the beginning of the shader. The static approach is a conservative estimate. The second approach is the dynamic programmer-directed approach. This method allows the developer to control the precision of each shader independently. Additional operations could be replaced with ripple-carry, carry-select, and brent-kung modules while multiplication operations could be replaced with single-gating, double-gating, and column-gating modules. The area overhead for these modules ranged from 9.3% – 34% while the delay penalty ranged from 0.4% – 6.9%. The simulator used was the ATTILA simulator. As the static approach is overly conservative in its error estimations, its energy conservation was not especially significant. However, the dynamic approach showed up to a 79% energy reduction in pixel shader arithmetic which is up to a 20% energy reduction for the GPU overall. [18] Although this method for saving energy clearly has costs to correctness and some performance overhead, it is viable for reducing energy consumption.
Results and Analysis
Due to time constraints and financial commitments, hardware testing and simulations were unable to be tested this semester. For future researchers, the possible focus on implementation to investigate energy consumption in high-performance computing environments can be performed given better time management and readily available hardware and software.
Conclusion
Energy reduction research is critical due to the high power consumption of most computing hardware today, and there have been significant improvements in possible solutions since the breakdown of Moore's law. Innovative solutions, such as chiplets and performance hybrid architecture, provide a promising future for processor technology by leveraging optimization of core usage, power-focused cores, and efficiency as the main point of focus. These solutions offer modularity, ease of scaling, reduced manufacturing costs, and optimized single-thread and multi-threaded performance with power-efficient and cost-effective cores. Despite the challenges posed by the increasing complexity of machine learning algorithms, these innovative solutions ensure continued advancements in computing efficiency and performance.
References
[1] S. Naffziger et al., "Pioneering Chiplet Technology and Design for the AMD EPYC™ and Ryzen™ Processor Families : Industrial Product," 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 2021, pp. 57-70, doi: 10.1109/ISCA52012.2021.00014.
[2] S. Naffziger, K. Lepak, M. Paraschou and M. Subramony, "2.2 AMD Chiplet Architecture for High-Performance Server and Desktop Products," 2020 IEEE International Solid- State Circuits Conference - (ISSCC), San Francisco, CA, USA, 2020, pp. 44-45, doi: 10.1109/ISSCC19947.2020.9063103.
[3] "4th gen AMD EPYC™ processor architecture | AMD," AMD. [Online]. Available: https://www.amd.com/en/campaigns/epyc-9004-architecture.
[4] "Skylake (client) - microarchitectures - intel," WikiChip. [Online]. Available: https://en.wikichip.org/wiki/intel/microarchitectures/skylake_(client).
[5] Z. Zhang, "Analysis of the Advantages of the M1 CPU and Its Impact on the Future Development of Apple," 2021 2nd International Conference on Big Data & Artificial Intelligence & Software Engineering (ICBASE), Zhuhai, China, 2021, pp. 732-735, doi: 10.1109/ICBASE53849.2021.00143.
[6] "Hybrid architecture (code name Alder Lake)," Intel. [Online]. Available: https://www.intel.com/content/www/us/en/developer/articles/technical/hybrid-architecture.html.
[7] E. Rotem et al., "Intel Alder Lake CPU Architectures," in IEEE Micro, vol. 42, no. 3, pp. 13-19, 1 May-June 2022, doi: 10.1109/MM.2022.3164338.
[8] "Apple unleashes M1," Apple Newsroom, 27-Feb-2023. [Online]. Available: https://www.apple.com/newsroom/2020/11/apple-unleashes-m1/.
[9] "Intel Architecture Day 2021 Presentation", Intel. [Online]. Available: https://download.intel.com/newsroom/2021/client-computing/intel-architecture-day-2021-presentation.pdf.
[10] "AMD EPYC™ 9004 series server processors | AMD," AMD. [Online]. Available: https://www.amd.com/en/processors/epyc-9004-series.
[11] "13th Gen Intel Core Desktop Media Presentation," Intel. [Online]. Available: https://download.intel.com/newsroom/2022/2022innovation/13th-Gen-Intel-Core-Desktop-Media-presentation.pdf.
[12] N. Guo et al., "Energy-Efficient Hybrid Analog/Digital Approximate Computation in Continuous Time," in IEEE Journal of Solid-State Circuits, vol. 51, no. 7, pp. 1514-1524, July 2016, doi: 10.1109/JSSC.2016.2543729.
[13] Z. Sun and D. Ielmini, “Tutorial: Analog Matrix Computing (AMC) with Crosspoint Resistive Memory Arrays,” arXiv, 2022. [Online]. Available: https://arxiv.org/ftp/arxiv/papers/2205/2205.05853.pdf. [Accessed: Mar-2023].
[14] B. Kocot, P. Czarnul and J. Proficz, "Energy-Aware Scheduling for High-Performance Computing Systems: A Survey," Energies, vol. 16, (2), pp. 890, 2023. Available: https://oregonstate.idm.oclc.org/login?url=https://www.proquest.com/scholarly-journals/energy-aware-scheduling-high-performance/docview/2767216639/se-2. DOI: https://doi.org/10.3390/en16020890.
[15] M. A. Z. Alves, M. C. Cera, J. V. F. Lima, N. Maillard, and P. O. A. Navaux, “Enhancing Energy Efficiency using Efficient Parallel Programming Techniques,” Departamento de Informatica Universidade Federal do Parana, 2010. [Online]. Available: https://web.inf.ufpr.br/mazalves/wp-content/uploads/sites/13/2021/04/clcar2010b.pdf. [Accessed: 15-Mar-2023].
[16] M. Rhu, M. Sullivan, J. Leng, and M. Erez, “A Locality-Aware Memory Hierarchy for Energy-Efficient GPU Architectures,” ACM Digital Library, 2013. [Online]. Available: https://dl-acm-org.oregonstate.idm.oclc.org/doi/epdf/10.1145/2540708.2540717. [Accessed: Mar-2023].
[17] A. Sankaranarayanan, E. K. Ardestani, J. L. Briz, and J. Renau, “An Energy Efficient GPGPU Memory Hierarchy with Tiny Incoherent Caches,” Micro Architecture Santa Cruz, 2013. [Online]. Available: https://masc.soe.ucsc.edu/docs/islped13.pdf. [Accessed: Mar-2023].
[18] J. Pool, A. Lastra, and M. Singh, “Precision Selection for Energy-Efficient Pixel Shaders,” ACM Digital Library, 2011. [Online]. Available: https://dl-acm-org.oregonstate.idm.oclc.org/doi/epdf/10.1145/2018323.2018349. [Accessed: Mar-2023].